Nel panorama digitale odierno, le basi di dati rappresentano il fondamento su cui si erge l’intero edificio dell’informatica moderna. Dallo scambio di messaggi su piattaforme sociali all’analisi di dati complessi per prendere decisioni aziendali cruciali, le basi di dati sono onnipresenti e indispensabili. Tuttavia, la loro importanza va ben oltre la mera raccolta di informazioni: risiede nella loro progettazione accurata, che ne determina l’efficienza, l’affidabilità e la capacità di adattamento ai cambiamenti tecnologici in rapida evoluzione.
Questi appunti si propongono di esplorare il fondamentale ruolo delle basi di dati nella società contemporanea, sottolineando l’importanza della loro progettazione oculata. Attraverso un viaggio nel mondo della progettazione delle basi di dati, esamineremo non solo le pratiche consolidate, ma anche le nuove sfide e opportunità che emergono con l’avanzamento della tecnologia.
Nel contesto di un’era in cui la quantità di dati generati e raccolti cresce in modo esponenziale, la progettazione delle basi di dati non è più un mero dettaglio tecnico, ma piuttosto una competenza chiave per l’efficace gestione delle informazioni.
Dati
I dati possono essere considerati come i “mattoni elementari” del mondo digitale. Sono rappresentazioni simboliche di informazioni, che possono essere numeri, testo, immagini, suoni, video e molto altro ancora. Da un semplice tweet su X a un’enorme raccolta di dati sull’andamento del mercato azionario, tutto ciò che incontriamo nell’ambiente digitale è composto da dati.
Negli ultimi decenni, abbiamo assistito a un’esplosione senza precedenti nella generazione e nell’acquisizione di dati. Questo fenomeno è stato alimentato dalla diffusione della tecnologia digitale in ogni aspetto della nostra vita quotidiana. Ogni volta che effettuiamo una ricerca su Internet, acquistiamo qualcosa online, pubblichiamo un post sui social media o utilizziamo un’applicazione sul nostro smartphone, stiamo generando dati. Inoltre, l’avvento di tecnologie come l’Internet delle cose (IoT), che connette dispositivi e sensori di ogni genere alla rete, ha amplificato esponenzialmente la quantità di dati generati.
Ma perché dovremmo preoccuparci così tanto dei dati? La risposta è semplice: i dati sono diventati il carburante che alimenta l’economia digitale e guida l’innovazione in molteplici settori. Ecco alcuni punti chiave che evidenziano l’importanza dei dati nell’era digitale:
- Pilastro dell’Economia Digitale: I dati sono diventati una risorsa strategica per le aziende di ogni settore. Le aziende utilizzano i dati per comprendere meglio i propri clienti, ottimizzare le operazioni aziendali, migliorare i prodotti e servizi e prendere decisioni più informate.
- Innovazione e Sviluppo Tecnologico: I dati alimentano l’innovazione tecnologica in molteplici settori, dalla sanità alla mobilità, dall’energia alla sicurezza. Tecnologie avanzate come l’intelligenza artificiale, l’apprendimento automatico e l’analisi dei dati sono alimentate dai dati stessi, aprendo nuove frontiere per il progresso umano.
- Miglioramento della Qualità della Vita: I dati possono essere utilizzati per affrontare sfide sociali ed economiche cruciali, come la sanità pubblica, l’istruzione, l’ambiente e la povertà. L’analisi dei dati può portare a soluzioni più efficaci e mirate per affrontare tali sfide, migliorando la qualità della vita per milioni di persone in tutto il mondo.
- Empowerment Individuale: In un mondo sempre più digitalizzato, il controllo e l’accesso ai propri dati possono rappresentare un potente strumento di empowerment individuale. Consentono alle persone di prendere decisioni più consapevoli sulla propria vita, la propria salute, le proprie finanze e altro ancora.
“Un dato è una rappresentazione simbolica di informazioni sotto forma di numeri, testo, immagini o qualsiasi altra forma, che può essere memorizzata, elaborata e trasferita dai computer.”
I dati sono elementi grezzi e privi di significato che, una volta elaborati, diventano informazioni utili per l’utente. Possono essere strutturati o non strutturati e sono la materia prima su cui si basano l’analisi, la decisione e molte altre attività nel contesto informatico e digitale.
Sorgenti di dati
Le fonti di dati sono le varie origini da cui provengono i dati, e possono essere sia digitali che fisiche. Esse costituiscono la base su cui vengono raccolte, generate e acquisite le informazioni che poi vengono utilizzate per analisi, elaborazione e presa di decisioni.

Dati generati dagli utenti
- Social Media: Piattaforme come Facebook, Twitter, Instagram, LinkedIn generano enormi quantità di dati ogni giorno sotto forma di post, commenti, likes, condivisioni, etc.
- Siti Web: I siti web raccolgono dati sugli utenti attraverso visite, clic, interazioni con il sito e compilazione di moduli.
- Applicazioni Mobile: Le app mobile raccolgono dati sugli utenti tramite l’utilizzo dell’app stessa, le azioni degli utenti all’interno dell’app e le loro preferenze.
- E-mail: I servizi di posta elettronica raccolgono dati sugli utenti attraverso messaggi inviati e ricevuti, filtri applicati, risposte e altro ancora.
Dati dei sensori
- Internet delle Cose (IoT): Dispositivi connessi come sensori ambientali, smart meters, telecamere di sorveglianza, dispositivi wearable, veicoli connessi, raccolgono dati in tempo reale sull’ambiente circostante, sulle prestazioni dei dispositivi stessi e sul comportamento degli utenti.
- Sensori Industriali: Le industrie utilizzano una varietà di sensori per monitorare e controllare i processi produttivi, raccogliendo dati su temperatura, pressione, umidità, vibrazioni, livelli di produzione, ecc.
Dati transazionali
- Acquisti Online: Le transazioni di acquisto online generano dati sulle preferenze di acquisto degli utenti, i prodotti acquistati, l’importo speso, ecc.
- Transazioni Finanziarie: Le transazioni bancarie, le transazioni con carta di credito e altre transazioni finanziarie generano dati che forniscono informazioni sulle abitudini di spesa degli individui e delle aziende.
Dati pubblici e governativi
- Dati Demografici: Le istituzioni governative raccolgono e pubblicano dati demografici sulla popolazione, come età, genere, etnia, reddito, istruzione, ecc.
- Dati Meteo: Le agenzie meteorologiche raccolgono dati meteo da stazioni di monitoraggio sparse in tutto il mondo, fornendo informazioni sulle condizioni meteorologiche attuali e previste.
- Dati Sanitari: I sistemi sanitari e le agenzie governative raccolgono dati sugli individui, compresi dati clinici, storico delle malattie, prescrizioni mediche, ecc.
Dati aziendali
- Dati di Produzione: Le aziende raccolgono dati sui processi di produzione, le prestazioni delle macchine, gli errori di produzione, ecc.
- Dati di Vendita: I negozi e le aziende raccolgono dati sulle vendite di prodotti, le preferenze dei clienti, le tendenze di mercato, ecc.
- Dati di Logistica: Le aziende di trasporto e logistica raccolgono dati sui movimenti delle merci, le consegne, i tempi di consegna, ecc.
Tipi di dati
Dati strutturati
I dati strutturati sono quelli organizzati in un formato rigido e predefinito, caratterizzati da colonne e righe che seguono uno schema definito. Un esempio classico di dati strutturati è rappresentato dalle tabelle in un database relazionale, in cui ogni riga corrisponde a un record e ogni colonna rappresenta un attributo specifico di quel record. Questa struttura ordinata facilita la ricerca, l’analisi e l’estrazione di informazioni in modo efficiente e affidabile. I database relazionali, con il loro linguaggio di interrogazione standardizzato (SQL), sono diventati il pilastro dell’archiviazione e della gestione dei dati aziendali. Le caratteristiche principali dei dati strutturati sono:
- Organizzazione Logica: I dati strutturati sono organizzati in modo logico all’interno di database relazionali, dove ogni elemento è strettamente definito e associato ad altri in base a relazioni specifiche. Questa organizzazione permette un accesso rapido e efficiente alle informazioni, migliorando la gestione e l’analisi dei dati.
- Facilità di Query: Grazie alla loro struttura tabellare, i dati strutturati sono facilmente interrogabili utilizzando linguaggi standardizzati come SQL (Structured Query Language). Questo consente agli utenti di recuperare informazioni specifiche con precisione e rapidità, rendendo l’analisi dei dati un processo efficiente e intuitivo.
- Affidabilità e Coerenza: Poiché i dati strutturati seguono uno schema predefinito, sono meno soggetti a errori e inconsistenze rispetto ai dati non strutturati. Questo assicura un elevato livello di affidabilità e coerenza nei risultati ottenuti dall’elaborazione dei dati.
- Integrazione dei Dati: La struttura standardizzata dei dati facilita l’integrazione e la condivisione tra diversi sistemi e applicazioni. Questo permette una maggiore collaborazione e interoperabilità tra i diversi attori all’interno di un’organizzazione o di un ecosistema più ampio.
- Sicurezza e Controllo dell’Accesso: I database strutturati consentono di implementare facilmente politiche di sicurezza e di controllo dell’accesso per proteggere le informazioni sensibili. Gli amministratori possono definire ruoli e privilegi specifici per garantire che solo gli utenti autorizzati possano accedere e modificare i dati.
Dati non strutturati
Diversamente dai dati strutturati, i dati non strutturati non seguono un formato predefinito e possono essere rappresentati in vari modi, come testo libero, immagini, audio, video e altro ancora. Questa forma di dati è onnipresente nel nostro mondo digitale, costituita da e-mail, documenti di testo, post sui social media, registrazioni video e molto altro ancora. La sfida principale nella gestione dei dati non strutturati risiede nella loro natura disorganizzata e nella mancanza di un formato standardizzato, il che rende difficile l’analisi automatizzata e l’estratto di significato da queste fonti.
I dati non strutturati sono caratterizzati dalle famocse 5V:
- Volume: Questa “V” si riferisce alla grande quantità di dati non strutturati generati e accumulati costantemente. Con l’avvento delle piattaforme sociali, dei sensori IoT, delle registrazioni video, delle e-mail e altro ancora, il volume di dati non strutturati è esploso a livelli enormi. La gestione e l’analisi di grandi volumi di dati rappresentano una sfida significativa per le organizzazioni, richiedendo infrastrutture e strumenti appositi per l’archiviazione, l’elaborazione e l’estrazione di valore da queste enormi masse di informazioni.
- Varianza: Questa “V” sottolinea la diversità e la complessità dei dati non strutturati. Questi possono assumere molte forme diverse, tra cui testo libero, immagini, audio, video, dati geospaziali e altro ancora. La varietà dei formati e delle strutture rende difficile la standardizzazione e la normalizzazione dei dati non strutturati, richiedendo approcci flessibili e strumenti avanzati per gestire questa diversità.
- Velocità: Questa “V” si riferisce alla velocità con cui i dati non strutturati vengono generati, elaborati e analizzati. Molte fonti di dati non strutturati producono informazioni in tempo reale o quasi reale, come i dati dei social media o i feed di sensori IoT. Affrontare questa velocità di generazione dei dati richiede sistemi e processi in grado di catturare, elaborare e rispondere rapidamente a flussi di dati in continuo cambiamento.
- Veridicità: Questa “V” riguarda l’affidabilità e la precisione dei dati non strutturati. Poiché questi dati spesso provengono da fonti eterogenee e possono essere influenzati da rumori o errori, è essenziale valutarne la qualità e la veridicità. Gli strumenti di analisi dei dati devono essere in grado di identificare e mitigare il rischio di dati inaffidabili o distorti, garantendo che le decisioni basate su tali dati siano accurate e affidabili.
- Valore: Questa “V” indica il potenziale valore che i dati non strutturati possono offrire quando vengono correttamente analizzati e sfruttati. Nonostante le sfide legate alla gestione e all’analisi dei dati non strutturati, questi possono contenere insight preziosi e informazioni strategiche per le organizzazioni. Sfruttare appieno il valore dei dati non strutturati richiede investimenti in tecnologie di analisi avanzate, competenze specializzate e una chiara strategia di gestione dei dati.
Dati Semistrutturati
Oltre alla dicotomia tra dati strutturati e non strutturati, esiste un’interessante categoria intermedia di dati semistrutturati. Questi dati mantengono una certa organizzazione, ma non rispettano pienamente lo schema rigido dei dati strutturati. Ad esempio, documenti XML e JSON contengono informazioni strutturate ma non seguono uno schema rigido come le tabelle dei database relazionali. I dati semistrutturati rappresentano una sfida unica nella progettazione delle basi di dati, richiedendo un approccio flessibile che possa gestire la complessità senza sacrificare l’efficienza.
Storia delle basi dati
Le basi di dati hanno le loro radici negli anni ‘60 quando nacquero i primi sistemi di gestione dei file, utilizzati per archiviare e organizzare dati su supporti di memoria fisica, come nastri magnetici e dischi rigidi. Questi sistemi, sebbene primitivi, hanno posto le basi per lo sviluppo dei database moderni. I problemi principali erano la ridondanza dei dati e l’incoerenza.
Nelle prime implementazioni delle basi di dati, la ridondanza dei dati era una sfida comune. Poiché i sistemi di gestione dei file erano la norma, i dati venivano spesso replicati in diversi file e locazioni all’interno di un sistema. Questo portava a una duplicazione non necessaria dei dati, occupando spazio di archiviazione prezioso e aumentando il rischio di errori e inconsistenze. Inoltre, la ridondanza poteva rendere difficile mantenere i dati aggiornati e sincronizzati tra le varie copie, portando a discrepanze e disallineamenti.
L‘incoerenza dei dati era un altro problema diffuso nei primi sistemi di gestione dei file e nelle prime implementazioni delle basi di dati. Poiché i dati venivano spesso gestiti in modo decentralizzato e senza una rigorosa gestione delle transazioni, potevano verificarsi situazioni in cui i dati incoerenti o contraddittori venivano immessi nel sistema. Ad esempio, un cliente potrebbe avere informazioni di contatto diverse in due file diversi, creando confusione e frustrazione sia per gli utenti che per il personale che utilizzava i dati.
Durante gli anni ’60, gli informatici hanno iniziato a sviluppare soluzioni per affrontare questi problemi di ridondanza e incoerenza dei dati. L’introduzione dei primi modelli di dati normalizzati, come il modello relazionale proposto da Edgar F. Codd alla fine degli anni ’60, ha fornito un quadro teorico per ridurre la ridondanza e garantire la coerenza dei dati attraverso la normalizzazione del database. Inoltre, l’implementazione di sistemi di gestione dei database relazionali (RDBMS) ha permesso una gestione più centralizzata e strutturata dei dati, migliorando la coerenza e riducendo la ridondanza attraverso l’uso di tabelle relazionali e chiavi primarie/esterne.
Negli anni ’70, nacquero i primi database relazionali, con il modello relazionale introdotto da Edgar F. Codd nel 1970. Questo modello proponeva una nuova modalità di organizzazione dei dati basata su tabelle interconnesse, che portava ad una maggiore flessibilità e scalabilità rispetto ai modelli precedenti.
Negli anni ’80 , ’90 l’avvento dei sistemi di gestione di database relazionali (RDBMS) come Oracle, IBM DB2 e Microsoft SQL Server ha portato la gestione dei dati a un nuovo livello di sofisticazione e diffusione. Le aziende iniziano a utilizzare i database relazionali per gestire informazioni critiche e supportare le operazioni aziendali.
Con l’avvento di Internet e la crescita esponenziale dei dati generati online, emerge negli anni 2000 la necessità di gestire grandi volumi di dati in modo efficiente ed efficace. In risposta a questa esigenza, nascono tecnologie come Apache Hadoop e NoSQL, progettate per gestire e analizzare enormi quantità di dati non strutturati e semi-strutturati.
Negli anni 2010 la diffusione della cloud computing e delle architetture distribuite porta a un cambiamento fondamentale nella progettazione delle basi di dati. I database distribuiti e i servizi di gestione dei dati in cloud come Amazon RDS, Google Cloud Spanner e Microsoft Azure SQL Database consentono alle organizzazioni di archiviare e gestire i propri dati in modo scalabile e altamente disponibile, senza dover investire in infrastrutture hardware costose.

Negli ultimi anni l’evoluzione continua delle tecnologie informatiche, tra cui l’intelligenza artificiale, l’analisi dei dati in tempo reale e l’Internet delle cose (IoT), sta plasmando il futuro delle basi di dati. Ci si aspetta che le basi di dati diventino sempre più intelligenti, autonome e capaci di gestire una vasta gamma di dati strutturati e non strutturati per supportare le crescenti esigenze delle organizzazioni nel mondo digitale in rapida evoluzione.
DBMS
Un Sistema di Gestione delle Basi di Dati (DBMS) è un software progettato per consentire la creazione, la gestione e l’interrogazione efficiente di grandi quantità di dati in un ambiente organizzato. I DBMS sono essenziali per organizzazioni di ogni dimensione e settore, poiché consentono di archiviare dati in modo strutturato e di accedervi in modo rapido ed efficiente.
I DBMS sono cruciali per molte ragioni:
- Organizzazione dei dati: I DBMS consentono di organizzare i dati in modo strutturato utilizzando tabelle, relazioni e altri metodi, rendendo più semplice la gestione e l’accesso ai dati.
- Accesso rapido ai dati: I DBMS utilizzano algoritmi sofisticati per consentire un recupero rapido dei dati, anche da enormi quantità di informazioni.
- Condivisione dei dati: I DBMS consentono a più utenti di accedere e modificare i dati contemporaneamente, garantendo al contempo l’integrità dei dati.
- Sicurezza: I DBMS offrono meccanismi di sicurezza avanzati per proteggere i dati sensibili da accessi non autorizzati.
- Integrità dei dati: I DBMS garantiscono che i dati siano accurati e consistenti, applicando regole di integrità e vincoli definiti dall’utente.
- Backup e ripristino: I DBMS offrono funzionalità per il backup regolare dei dati e il ripristino in caso di errori o disastri.
Struttura DBMS
I DBMS sono composti da diversi componenti:
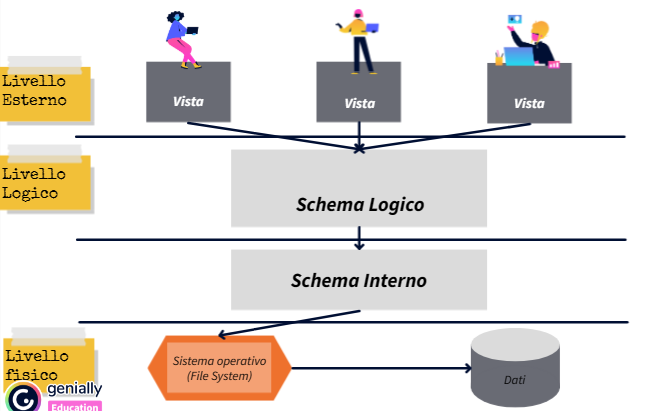
1. Livello Esterno
Il livello esterno, o livello dell’utente, è la parte del DBMS che interagisce direttamente con gli utenti o le applicazioni. Questo livello è composto da viste, che rappresentano una proiezione dei dati per soddisfare le esigenze specifiche degli utenti o delle applicazioni. Le viste forniscono un’interfaccia personalizzata per accedere ai dati, nascondendo i dettagli di implementazione sottostanti e semplificando così l’accesso ai dati per gli utenti.
2. Livello Logico
Il livello logico definisce la struttura logica del database, includendo lo schema logico. Lo schema logico descrive la struttura dei dati in termini di tabelle, relazioni e vincoli. Questo livello fornisce una rappresentazione astratta dei dati e delle relazioni tra di essi, indipendentemente dalla loro implementazione fisica. Gli utenti interagiscono con il database attraverso lo schema logico, definendo e manipolando i dati utilizzando query e comandi di manipolazione dei dati (DML).
3. Livello Fisico
Il livello fisico descrive come i dati sono memorizzati e accessibili dal sistema informatico sottostante. È composto da due componenti principali:
- Schema Interno: Lo schema interno definisce la struttura fisica dei dati, inclusi i dettagli di memorizzazione, indicizzazione e accesso. Questo schema specifica come i dati sono effettivamente organizzati su disco e gestiti dal sistema di archiviazione del DBMS.
- Livello Fisico: Il livello fisico comprende il sistema operativo, il file system e i dati effettivi memorizzati su disco. Questo livello si occupa della gestione delle operazioni di input/output (I/O) per accedere e manipolare i dati nel sistema di archiviazione.
Tipi di DBMS
Esistono diversi tipi di DBMS, tra cui:
- Relazionale: Basato sul modello relazionale, in cui i dati sono organizzati in tabelle relazionali.
- Oggetto: Consente di memorizzare dati complessi, come immagini e audio, in un database.
- Gerarchico: Organizza i dati in una struttura ad albero.
- Rete: Utilizza una struttura a grafo per rappresentare le relazioni tra i dati.
- Distribuito: Consente di distribuire i dati su più server.
- NoSQL: Ottimizzato per la gestione di grandi volumi di dati non strutturati o semi-strutturati.
Progettazione di Basi Dati
La progettazione di una base di dati è un processo complesso che richiede una pianificazione attenta e una comprensione approfondita dei requisiti del sistema e dei dati coinvolti. Di seguito, fornisco una panoramica dettagliata del processo di progettazione di una base di dati:
1. Analisi dei Requisiti
Il primo passo nella progettazione di una base di dati è l’analisi dei requisiti. Questo coinvolge la comprensione completa delle esigenze del sistema, inclusi i requisiti funzionali e non funzionali. Gli analisti di sistema lavorano a stretto contatto con gli utenti finali e gli stakeholder per identificare i requisiti del sistema, i flussi di lavoro, le regole di business e altre considerazioni importanti.
2. Concettualizzazione del Modello dei Dati
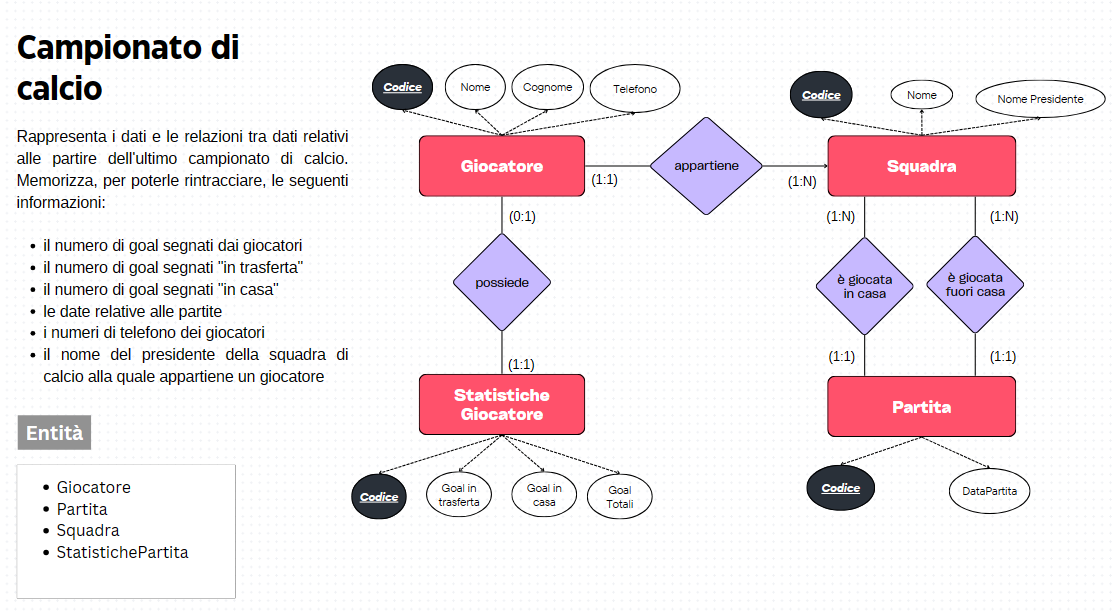
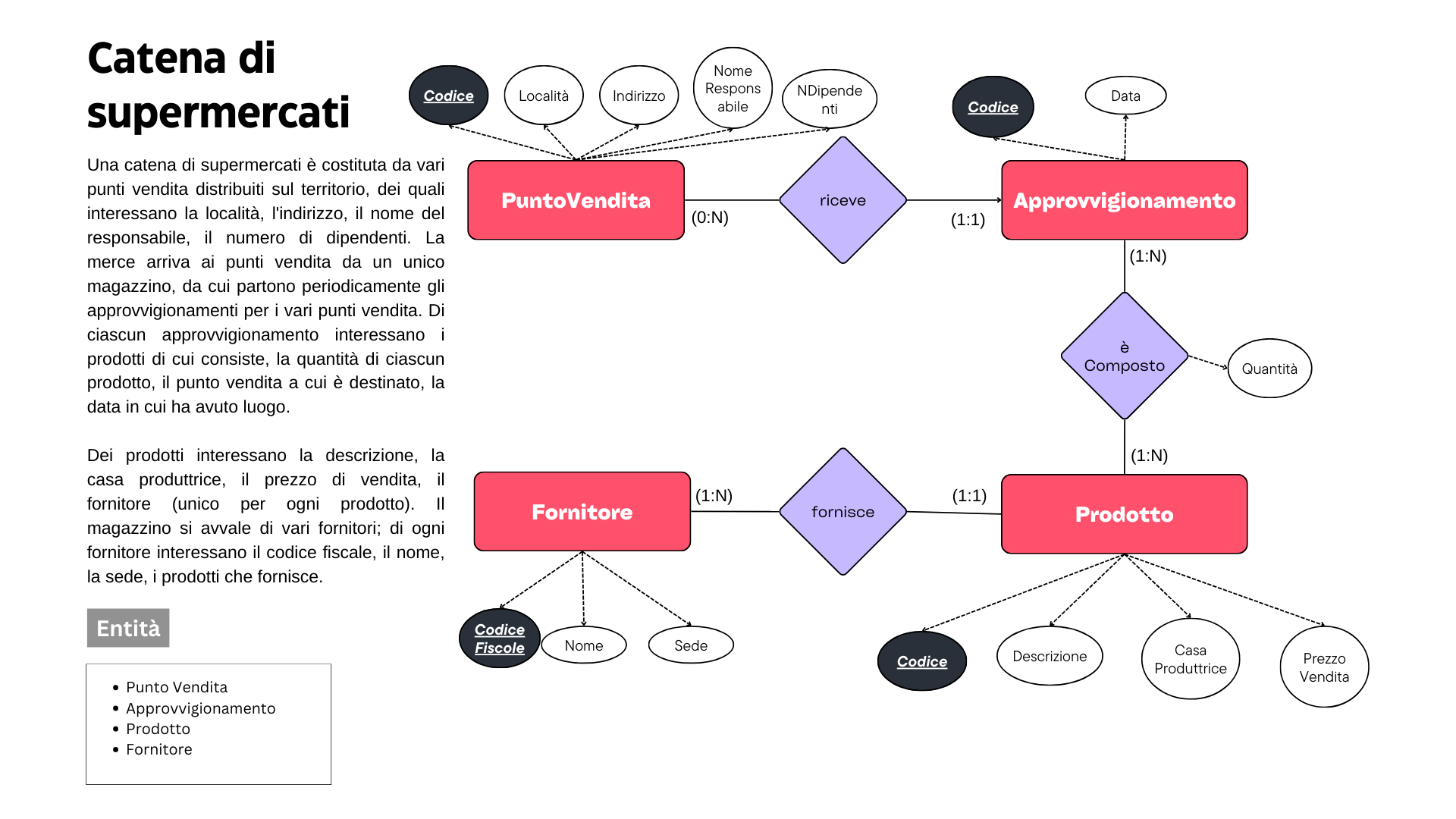
Basandosi sui requisiti raccolti durante l’analisi, i progettisti creano un modello concettuale dei dati. Questo modello rappresenta le entità principali coinvolte nel sistema e le relazioni tra di esse, indipendentemente dall’implementazione tecnica. Diagrammi Entity-Relationship (ER) sono spesso utilizzati per rappresentare il modello concettuale, evidenziando le entità, gli attributi e le relazioni.
3. Progettazione dello Schema Logico
Dopo aver stabilito il modello concettuale, i progettisti traducono questo modello in uno schema logico dei dati. Lo schema logico definisce la struttura dei dati in termini di tabelle, attributi e vincoli di integrità. Durante questa fase, vengono definite le tabelle principali, i loro attributi e le chiavi primarie e esterne. Si tratta essenzialmente di trasformare il modello concettuale in uno schema di database relazionale.
4. Normalizzazione dei Dati
La normalizzazione è un processo importante durante la progettazione dello schema logico. L’obiettivo della normalizzazione è eliminare la ridondanza dei dati e garantire l’integrità e la coerenza dei dati. Questo processo coinvolge la suddivisione delle tabelle in strutture più piccole e atomiche, riducendo al minimo la duplicazione dei dati e garantendo che ogni entità abbia una chiave primaria unica.
5. Ottimizzazione delle Prestazioni
Durante la progettazione dello schema logico, è importante considerare le prestazioni del database. Questo include l’identificazione di opportunità per l’ottimizzazione delle query, la creazione di indici appropriati e la valutazione delle strategie di accesso ai dati. Gli aspetti da considerare includono la frequenza e il tipo di query eseguite sul database, la dimensione dei dati e le risorse hardware disponibili.
6. Implementazione Fisica
Una volta completato lo schema logico, il prossimo passo è l’implementazione fisica del database. Questo coinvolge la creazione effettiva delle tabelle e degli indici nello schema di database utilizzando il linguaggio di definizione dei dati (DDL) del DBMS scelto. Durante questa fase, vengono anche applicati i vincoli di integrità definiti nello schema logico.
7. Testing e Ottimizzazione
Una volta che il database è stato implementato, è importante condurre test approfonditi per verificare la correttezza e le prestazioni del sistema. Questo include test di integrità dei dati, test di unità per i singoli componenti del database e test di integrazione per verificare che il sistema funzioni correttamente nel suo insieme. In base ai risultati dei test, possono essere apportate modifiche e ottimizzazioni al database.
8. Manutenzione e Evoluzione
La progettazione di una base di dati è un processo continuo che richiede manutenzione e aggiornamenti nel tempo. Gli sviluppatori devono monitorare le prestazioni del database, applicare patch di sicurezza e fare eventuali modifiche ai requisiti del sistema. Inoltre, possono essere necessari aggiornamenti dello schema di database per supportare nuove funzionalità o requisiti aziendali in evoluzione.
Torna a basi di dati