I vincoli di integrità in un database relazionale sono regole o restrizioni che vengono applicate ai dati per garantire che rimangano coerenti, accurati e conformi alle specifiche del database. Consideriamo ad esempio la seguente base di dati:
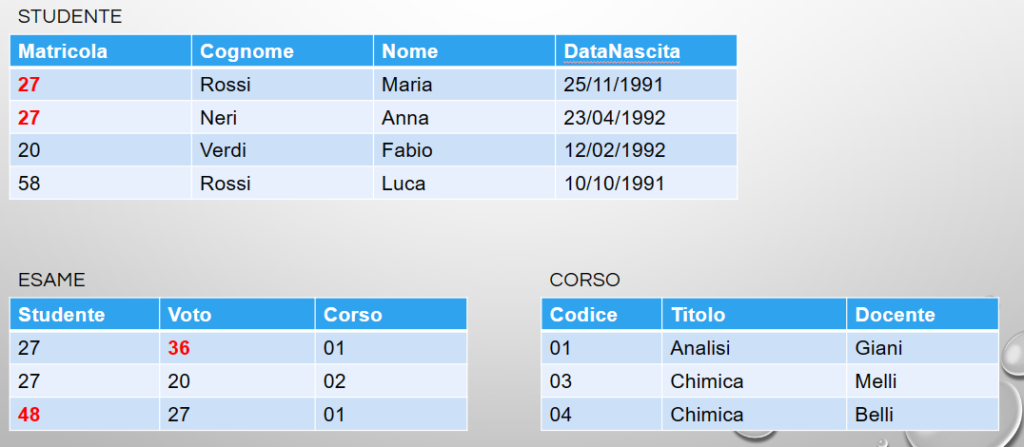
Come vediamo in questo scenario esistono dei problemi sui dati:
- nella relazione studente sono presenti due tuple che hanno la stessa matricola e questo non dovrebbe essere possibile visto che la matricola dovrebbe essere un attributo che identifica le singole tuple;
- nella relazione esame è presente uno studente che ha preso come voto 36 e di solito i voti sono espressi da 0 a 30
- sempre nella relazione esame è presente lo studente identificato dal codice 48 che non è un codice presente fra le matricole quindi non si sa a chi si riferisce.
Da questi esempi possiamo capire come sia fondamentale definire dei vincoli per gli schemi di relazione e più in generale per lo schema di base di dati. Questi vincoli di integrità possono essere suddivisi in due categorie principali: vincoli di integrità intrarelazionali e vincoli di integrità interrelazionali.
Vincoli intrarelazionali
I vincoli di integrità intrarelazionali sono regole che vengono applicate all’interno di una singola tabella o relazione. Questi vincoli mirano a mantenere l’integrità dei dati all’interno della stessa tabella. Ecco alcuni esempi comuni:
Vincolo di chiave
Il vincolo di chiave permette di identificare univocamente una tupla all’interno di una relazione. Prima di comprendere cosa sia una chiave è necessario definire il concetto di superchiave.
Una superchiave è un insieme di uno o più attributi in una relazione che consente di identificare in modo univoco ciascuna tupla nella relazione
Sia R una relazione con schemi
R(A1, A2, …, An)
e K un sottoinsieme degli attributi di R
K ⊆ {A1, A2, …, An}
K è una superchiave per R se, per ogni coppia di tuple t1 e t2 in R, se t1[K] = t2[K], allora t1 e t2 rappresentano la stessa tupla in R.
In definitiva possiamo affermare che le superchiavi sono un concetto più ampio rispetto alle chiavi, poiché possono essere sovra-determinate (contenere più colonne di quelle necessarie per l’identificazione univoca). Prendiamo ad esempio la seguente relazione:
Corso(Codice, Titolo, Docente)| Codice | Titolo | Docente |
| 01 | Analisi | Giani |
| 03 | Chimica | Melli |
| 04 | Chimica | Melli |
L’insieme K1 = {Titolo,Docente} non può essere superchiave in quanto se prendiamo le tuple {(03,Chimica,Melli), (04,Chimica,Melli)} osserviamo che pur essendo diverse (quindi t1 ≠ t2) i valori assunti dagli attributi nelle tuple sono uguali t1[K1] = t2[K1]. Per definizione un insieme di attributi K è superchiave se non contiene due tuple distinte t1 e t2 con t1[K]=t2[K]
L’insieme K2 = {Codice, Titolo} si può definire superchiave per la relazione perchè qualunque coppia di tuple consideriamo se il valore assunto dagli attributi codice è titolo è uguale anche le tuple saranno uguali.
In questa definizione, “t1[K]” rappresenta il sottoinsieme di attributi K nella tupla t1. Quindi, K è una superchiave se il suo valore è sufficiente per identificare univocamente ciascuna tupla all’interno della relazione R. Se due tuple condividono gli stessi valori per gli attributi nella superchiave K, allora sono considerate la stessa tupla nella relazione.
Una “chiave” (o “chiave primaria”) è una superchiave minimale, il che significa che è la più piccola superchiave possibile che può ancora identificare in modo univoco ogni riga nella tabella.
In altre parole, una chiave è una superchiave con il minimo numero di attributi richiesto per garantire l’unicità delle tuple.
Nell’esempio precedente abbiamo detto che l’insieme K2 = {Codice, Titolo} è superchiave ma non grazie all’attributo Titolo che potrebbe essere lo stesso per più tuple ma grazie al Codice che di fatto è sufficiente per identificare ogni singola tupla.
Quando un attributo di uno schema di relazione è chiave, è necessario sottolinearlo.
Vincolo di check
Un vincolo di check, noto anche come “constraint di check“, è un tipo di vincolo di integrità nei database relazionali che definisce condizioni o regole specifiche che i dati devono soddisfare per essere considerati validi. Queste condizioni sono definite dall’amministratore del database durante la progettazione del database e vengono applicate per garantire che i dati rispettino determinate restrizioni o requisiti.
Il vincolo di check permette di specificare condizioni personalizzate basate su espressioni logiche o funzioni definite dall’utente. Queste condizioni possono coinvolgere uno o più attributi della tabella.
Quando si inseriscono o si aggiornano i dati nella tabella, il vincolo di check verifica se le condizioni definite vengono soddisfatte. Se una condizione non è rispettata, l’operazione di inserimento o aggiornamento viene respinta e i dati non vengono accettati nel database.
Supponiamo di avere una tabella “Prodotti” e vogliamo assicurarci che il campo “Quantità” contenga solo valori positivi. Un vincolo di check per questo scopo potrebbe essere definito come segue:
Prodotto(Codice, Nome, Quantità)
CHECK Quantità > 0
Vincolo Unique
Un vincolo UNIQUE in un database relazionale è un tipo di vincolo di integrità che garantisce che i valori in un campo o in un insieme di campi siano univoci all’interno di una tabella. Questo significa che nessun valore duplicato è consentito nel campo o nell’insieme di campi soggetti al vincolo UNIQUE. Il vincolo UNIQUE assicura che i dati siano coerenti e non ci siano duplicati all’interno della tabella.
Al contrario del vincolo di chiave potrebbe ammettere anche dei valori nulli.
Supponiamo di avere una tabella “Clienti” e vogliamo garantire che l’indirizzo email dei clienti sia univoco. La definizione del vincolo UNIQUE sarebbe simile a questa:
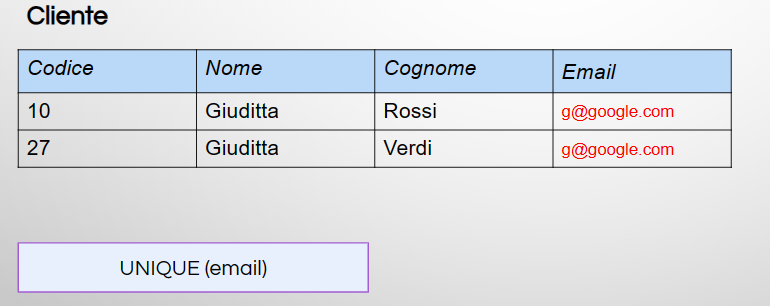
Cliente(Codice, Nome, Cognome, Email)
UNIQUE (Email)
Vincolo di integrità referenziale
Il vincolo di integrità referenziale è una regola o un insieme di regole nei database relazionali che garantiscono la coerenza e la consistenza dei dati tra tabelle correlate. In altre parole, assicura che le relazioni tra i dati in diverse tabelle siano mantenute e rispettate per evitare situazioni inconsistenti o errate nei dati.
Un vincolo di integrità referenziale è implementato mediante l’uso di chiavi esterne. La chiave esterna in una tabella fa riferimento alla chiave primaria di un’altra tabella. Questo vincolo impone che i valori nella colonna della chiave esterna devono corrispondere ai valori presenti nella colonna della chiave primaria della tabella di riferimento. In altre parole, i dati nella tabella con la chiave esterna devono fare riferimento solo a dati validi presenti nella tabella collegata.
Torna a Relazioni
Torna a Schema Relazionale