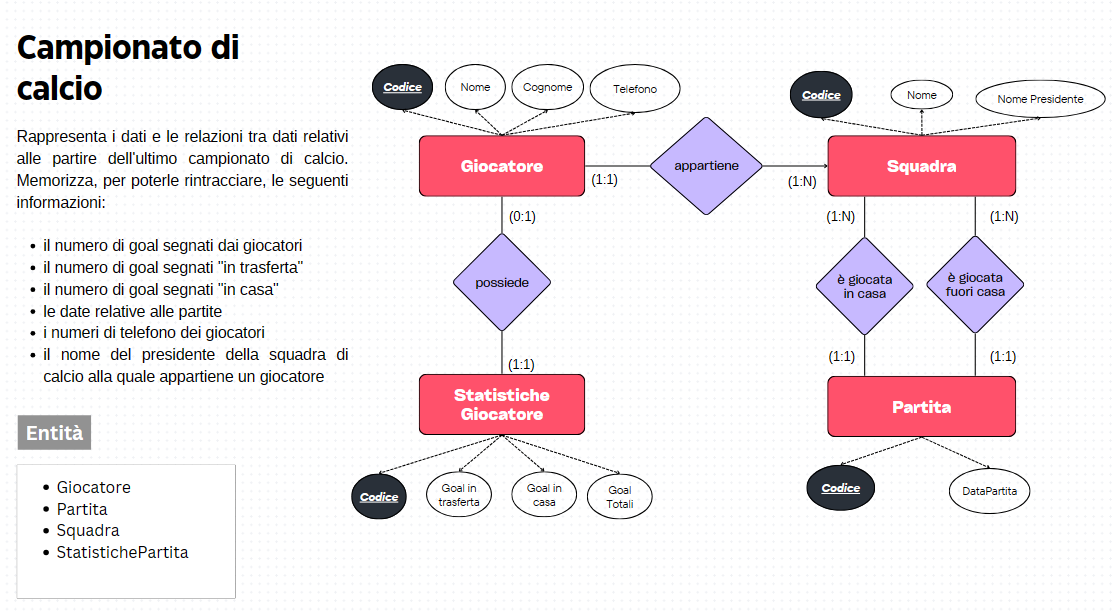
Machine Learning (ML) è una sottodivisione dell’intelligenza artificiale (IA) che consente ai computer di apprendere e migliorare le proprie prestazioni senza essere esplicitamente programmati. Attraverso l’utilizzo di algoritmi e modelli statistici, i sistemi di machine learning analizzano ed elaborano grandi quantità di dati, imparando da essi per fare previsioni o prendere decisioni basate sull’input ricevuto. Questa capacità di apprendimento automatico apre la strada a un’ampia gamma di applicazioni, dalla personalizzazione delle esperienze utente nei servizi online fino al miglioramento delle diagnosi mediche. Con il susseguirsi delle innovazioni tecnologiche, il machine learning sta rivoluzionando il modo in cui interagiamo con il mondo digitale, rendendo i servizi più intelligenti e intuitivi.
Il Machine Learning (ML) e la programmazione tradizionale differiscono significativamente nel loro approccio a risolvere problemi e nell’elaborazione dei dati.
- Programmazione Tradizionale: Si basa su regole esplicite stabilite dal programmatore. Il programmatore scrive codice che esegue specifiche istruzioni per produrre un risultato a partire da input definiti. Gli algoritmi e le logiche devono essere dettagliatamente specificati dallo sviluppatore in anticipo.
- Machine Learning: Si basa sull’apprendimento da dati. Invece di programmare esplicitamente ogni possibile condizione e azione, un modello di ML impara le relazioni tra input e output dai dati di esempio. Con il tempo e esempi aggiuntivi, il modello diventa più preciso nelle sue previsioni o classificazioni.

Utilizzi del Machine Learning
Il Machine Learning (ML) ha trovato applicazione in numerosi settori, rivoluzionando molti aspetti della vita quotidiana e dell’ambiente lavorativo. Tra i principali ambiti in cui il ML ha un impatto significativo troviamo:
Sanità
Nel settore sanitario, il ML contribuisce a migliorare la diagnosi precoce delle malattie, personalizzare le terapie e monitorare la salute dei pazienti in tempo reale. Algoritmi avanzati analizzano immagini mediche, prevedono l’evoluzione di patologie e assistono i medici nell’identificare il trattamento ottimale per ciascun paziente.
Finanza
Le istituzioni finanziarie utilizzano il machine learning per il rilevamento delle frodi, la gestione del rischio, l’automazione degli investimenti e l’analisi del credito. Gli algoritmi possono identificare modelli sospetti di transazioni per prevenire attività fraudolente e ottimizzare le strategie di trading.
Retail
Il settore retail sfrutta il ML per personalizzare l’esperienza d’acquisto attraverso raccomandazioni di prodotti, gestione delle scorte e previsioni di vendita. L’analisi dei dati dei clienti permette alle aziende di anticipare le tendenze e adeguare le scorte in modo dinamico.
Trasporti
Nel campo dei trasporti, il machine learning gioca un ruolo chiave nello sviluppo di veicoli autonomi e sistemi di navigazione. Elabora inoltre dati su traffico e abitudini degli utenti per ottimizzare percorsi e orari di mezzi pubblici, riducendo tempi di attesa e congestione.
Industria Manifatturiera
L’industria manifatturiera impiega il ML per prevedere guasti nelle macchine, migliorare i processi di controllo di qualità e ottimizzare le catene di montaggio. L’analisi predittiva contribuisce a ridurre i tempi di inattività e a mantenere elevati standard qualitativi.
Agricoltura
Nell’agricoltura moderna, il machine learning aiuta a monitorare la salute delle colture, ottimizzare l’uso di risorse come acqua e fertilizzanti e massimizzare i rendimenti. Droni e sensori raccolgono dati che, analizzati da modelli di ML, informano decisioni agronomiche precise e tempestive.
Intrattenimento
Il settore dell’intrattenimento utilizza il ML, specialmente nei servizi di streaming, per personalizzare i consigli su film e musica in base ai gusti degli utenti. Inoltre, il ML consente di analizzare e prevedere le tendenze culturali e di audience.
Sicurezza
I sistemi di sicurezza integrano il machine learning per il riconoscimento facciale, l’analisi del comportamento e la sorveglianza intelligente. Ciò migliora l’efficacia del monitoraggio e la risposta rapida a minacce potenziali.
Ricerca e Sviluppo (R&D)
La ricerca scientifica beneficia enormemente del ML, che accelera la scoperta di nuovi materiali, farmaci e tecnologie. Analisi complesse che richiederebbero anni possono essere condotte in tempi molto più brevi.
Educazione
L’istruzione personalizzata e l’analisi predittiva del rendimento degli studenti sono solo due esempi di come il ML stia cambiando il settore dell’educazione. Gli algoritmi possono adattare i materiali di apprendimento al livello di ogni studente e monitorare i progressi per intervenire tempestivamente in caso di difficoltà.
Tipi di machine learning
Il Machine Learning (ML) è un campo vasto e in continua evoluzione che si articola principalmente in tre categorie: apprendimento supervisionato, apprendimento non supervisionato e apprendimento per rinforzo. Nell’apprendimento supervisionato, il modello viene addestrato su un insieme di dati etichettati, ovvero ogni esempio nel set di dati ha un’etichetta o una risposta corretta associata. Questo approccio è ampiamente utilizzato per compiti di classificazione e regressione. L’apprendimento non supervisionato, invece, si concentra sull’identificazione di modelli o di strutture intrinseche nei dati che non sono etichettati; è utile per compiti quali il clustering o la riduzione della dimensionalità. Infine, l’apprendimento per rinforzo si basa sull’idea di agenti che apprendono a prendere decisioni ottimali attraverso ricompense e punizioni; è particolarmente efficace in ambienti dinamici e per la risoluzione di problemi complessi dove le sequenze di azioni influenzano l’outcome. Ognuna di queste categorie ha le sue tecniche e algoritmi specifici, e la scelta di quale utilizzare dipende dalla natura del problema e dai dati disponibili.
Apprendimento supervisionato
L’apprendimento supervisionato è un tipo di apprendimento automatico in cui un modello viene “istruito” usando un set di dati con esempi già etichettati. L’obiettivo è che il modello impari a svolgere un compito simile a quello per cui è stato addestrato, su dati nuovi e mai visti prima.
Esistono due tipi principali di apprendimento supervisionato: regressione e classificazione.
Regressione
Nella regressione, il modello impara a prevedere un valore numerico continuo. Un esempio di regressione potrebbe essere quello di prevedere il rendimento scolastico in base a valori precedentemente memorizzati:
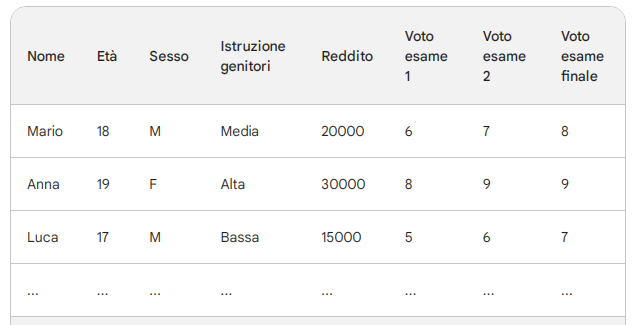
In questo modo dato un nuovo studente posso tentare di prevedere il ssuo voto di esame finale.
Altri esempi sono:
- Prevedere il prezzo di una casa in base a caratteristiche come la metratura, il numero di stanze e la posizione.
- Stimare il tempo di percorrenza di un viaggio in base al traffico e alle condizioni meteorologiche.
Classificazione
La classification, nel contesto dell’apprendimento automatico (o machine learning), è una tecnica usata per predire la categoria a cui appartiene un certo dato. Nella classificazione, il modello impara a prevedere una categoria discreta. La natura fondamentale del processo di classificazione è assegnare ogni istanza di dati a una categoria specifica basata su un insieme di caratteristiche. In sostanza la classificazione differisce dalla regressione perchè la previsione non viene effettuata su valori numerici ma su categorie. Esistono diversi tipi di modelli di classificazione, tra cui:
- Alberi decisionali (Decision Trees): strutture simili a grafici che usano una serie di decisioni basate su regole per guidare la classificazione.
- Support Vector Machines (SVM): metodi che trovano il miglior limite, o iperpiano, che separa le diverse categorie di dati.
- Reti neurali (Neural Networks): sistemi computazionali ispirati al funzionamento del cervello umano, estremamente efficaci per problemi di classificazione complessi.
- K-nearest neighbors (KNN): un metodo che classifica una nuova istanza di dati in base alla somiglianza con le ‘K’ istanze più vicine nel set di allenamento.
Ogni nuovo set di dati o problema specifico può richiedere un tipo diverso di modello di classificazione o una combinazione di tecniche, per cui è fondamentale comprendere le caratteristiche e i requisiti del problema per scegliere l’approccio più appropriato.
Esempi di classificazione potrebbero essere:
- Riconoscere se un’immagine contiene un gatto o un cane.
- Classificare le email come spam o posta in arrivo.
Apprendimento non supervisionato
L’apprendimento non supervisionato è un ramo dell’apprendimento automatico che si concentra sull’analisi di dati non etichettati. In questo tipo di apprendimento, l’algoritmo non riceve alcuna informazione predefinita sulle relazioni tra i dati, ma deve scoprire autonomamente le strutture e i pattern nascosti.
Le tecniche di apprendimento non supervisionato possono essere utilizzate per una varietà di compiti, tra cui:
- Clustering: raggruppare i dati in base a similarità e schemi nascosti.
- Association: scoprire relazioni tra diverse variabili in un dataset.
Apprendimento con rinforzo
L’apprendimento con rinforzo (Reinforcement Learning – RL) si occupa di come gli agenti possano imparare a prendere decisioni, massimizzando una qualche nozione di ricompensa cumulativa attraverso l’esperienza. Questo paradigma di apprendimento si ispira al modo in cui gli esseri viventi apprendono dalle conseguenze delle proprie azioni, sfruttando feedback positivi o negativi per migliorare il proprio comportamento nel tempo.
L’obiettivo dell’apprendimento con rinforzo è quello di trovare una politica ottimale che massimizzi le ricompense cumulative ricevute dall’agente nel tempo. Questo viene solitamente realizzato attraverso un processo di prova ed errore, in cui l’agente esplora diverse azioni e impara dalle ricompense ricevute.
Torna ad Intelligenza Artificiale